Datasets must be split into TRAINING and TESTING sets to use machine learning modeling methods. The following will describe and illustrate this and will share code in R and in Python.
There are many Machine Learning modeling techniques.
Some ML Modeling methods are:
- Decision Trees
- Random Forest
- Support Vector Machines
- Naive Bayes
- Neural Networks
- Regression
What does it mean to “model data for prediction or classification”?
To answer this question, let’s look at a simple and very small dataset.
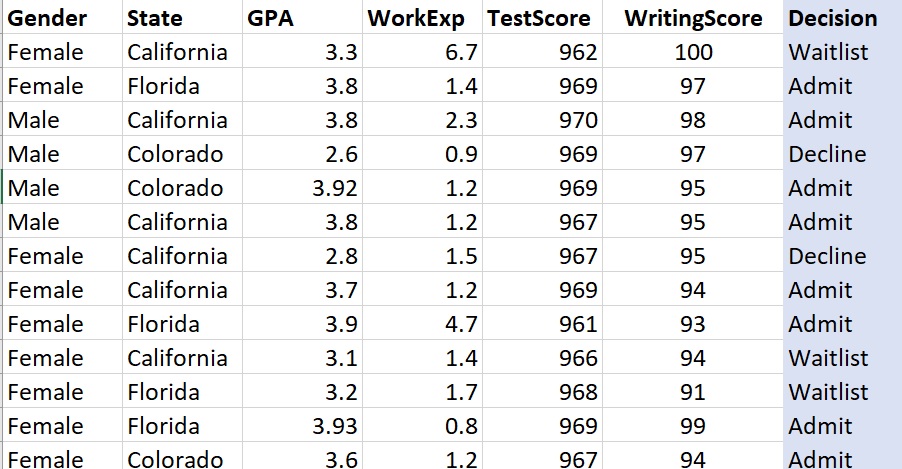
This dataset describes pretend data collected about potential students who applied to a summer program. First, notice that this is labeled data. That means that each row is a member of a category. In this case, we have three categories, “Admit”, “Waitlist”, and “Decline”.
Now, imagine that we collected this data (as decisions were made) over many years. By collecting this data, we can start to see patterns about which potential students are admitted, waitlisted, or declined. The variables in this case Gender, State (of residence), GPA, Work Experience, Test Score, and Writing Score.
Look at the data. Can you see a pattern?
Suppose I told you that a new potential student applied and that the vector/row that descibes the new potential student is:
Female, Florida, 3.0, 1.2, 880, 94
Can you GUESS the label for this potential student? In other words, can you use the dataset above, find patterns, and then use those patterns to PREDICT whether this student is likely to be classified as Admit, Waitlist, or Decline?
In this case, a fair prediction would be Waitlist because it appear that GPA is strongly correlated to the admission label. Of course, this is an overly simplified example.
Do you think a computer (via R or Python, etc) could LEARN the patterns and make a prediction?
The answer is – sometimes 🙂
If the dataset is accurate, clean, labeled, and non-chaotic (meaning there are patterns), then a computer model can detect and model those patterns.
This is exactly what machine learning methods/models try to do.
There are several tutorials that focus on machine learning methods and models.
HERE – we will talk about Training the Model and then Testing the model using our dataset. For example, if we want to see if an ML model can be created to accurately predict an outcome, such as what we did with the new potential student example above, then we can use a labeled dataset to TRAIN the model.
What is TRAINING A MODEL?
Training a model is “showing” a machine learning method a dataset with KNOWN LABELS so that it can LEARN how to predict a label for a new data row (vector) for which the label is not known.
We also want to be able to TEST OUR MODEL for accuracy.
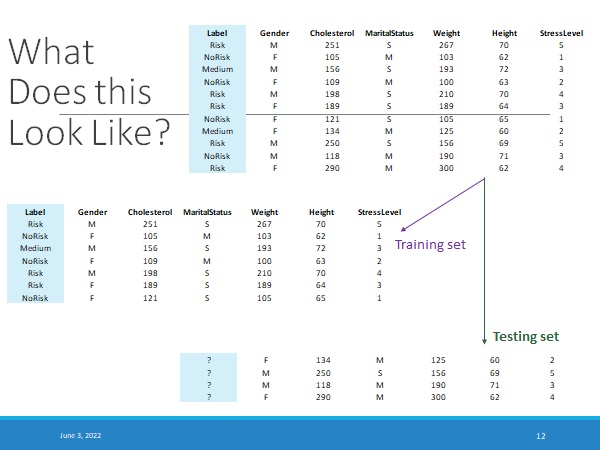
We need two SPLIT our labeled dataset into two parts – the TRAINING DATA and the TESTING DATA.
There should be NO OVERLAP between the training data portion and the testing data portion.
STEPS:
- Read in and clean (fully) the dataset.
- If you plan to add features – do so before splitting into training and test sets.
- If you plan to normalize or transform the data, again, do this first.
- Once the dataset is fully ready for analysis, take a fraction of the data and save it as TRAINING DATA and then use the remainder of the data and save it as TESTING DATA.
- Train your ML model with the TRAINING DATA.
- Test the accuracy of your ML model with the TESTING DATA.
Example code in R (two options) for breaking a dataset into a training set and a testing set and then removing the labels from the testing set. (There is a Python example at the very bottom of the page)
##########################################################
##
## Create the Testing and Training Sets in R - two options
##
########################################################
#####################################################
## Grabbing Every X value ##################
####################################################
##
## This method works whether the data is in order or not.
X = 3 ## This will create a 1/3, 2/3 split.
## Of course, X can be any number.
(every_X_index<-seq(1,nrow(Labeled_DF_Novels),X))
## Use these X indices to make the Testing and then
## Training sets:
DF_Test<-Labeled_DF_Novels[every_X_index, ]
DF_Train<-Labeled_DF_Novels[-every_X_index, ]
## View the created Test and Train sets
(DF_Test[1:5, 1:5])
(DF_Train[1:5, 1:5])
## Use tables to check the balance...
## WARNING - do not do this is you have high D data !!!
##sapply(DF_Test, table) ## Looks good!
##sapply(DF_Train, table) ## Looks good!
################ OK - now we have a Training Set
############### and a Testing Set.
###############################################
####### RANDOM SAMPLE OPTION FOR
###### Creating TRAINING and TESTING data
#########
###############################################
set.seed(1234) ## The number inside can be anything
(YourSampleSize <- (as.integer(nrow(Labeled_DF_Novels)/3)))
(My_SAMPLE <- sample(nrow(Labeled_DF_Novels), YourSampleSize))
DF_Test_R<-Labeled_DF_Novels[My_SAMPLE, ]
DF_Train_R<-Labeled_DF_Novels[-My_SAMPLE, ]
## View the created Test and Train sets
(DF_Test[, 1:5])
(DF_Train[, 1:5])
###############################################################
##
## NAIVE BAYES
##
###############################################################
#### !!!!!!!!!!!!! REMOVE and keep Labels from Test set !!!!!
##
##-----------------------------------------------------------------
## Make sure label is factor type
str(DF_Test)
## Copy the Labels
(Test_Labels <- DF_Test[,1])
str(Test_Labels)
## Remove the labels !!!
DF_Test_NO_LABEL <- DF_Test[,-c(1)]
(DF_Test_NO_LABEL[1:5, 1:5])
## Check size
(ncol(DF_Train))
####### RUN Naive Bayes --------------------------------------------
DF_Train
NB_e1071_2<-naiveBayes(DF_Train, DF_Train$MyNamesList, laplace = 1)
NB_e1071_Pred <- predict(NB_e1071_2, DF_Test_NO_LABEL)
#NB_e1071_2
table(NB_e1071_Pred,Test_Labels)
(NB_e1071_Pred)COMMON QUESTIONS:
- What size should the training data be relative to the testing data? For example, if you have 1000 rows of data, how many will go into the training set?
ANSWER: As with most things in data science (and in life 🙂 it depends. We want to use as much data as we can to train the model. The more data we use to train it, the more accurate the model should be (assuming that we can use the data for prediction). However, we also want to fairly test the model. Common splits for large datasets (more than 1000 rows) is 9/10 training and the remaining 1/10 for testing. Other variations in real-life can be 4/5 and 1/5, etc. I often use 1/7 and 6/7. Why? no real reason 🙂 There is no rule for this.
2. Is the training set generally larger than the testing set?
ANSWER: In my experience, yes.
3. Can you build (train) a machine learning model if you do not have labeled data?
ANSWER: No! and it is very important to understand why. If you do not have labels, then you cannot teach a computer how to predict labels that are not there 🙂
4. What if your data is not balanced? For example, what if 90% of your data all belongs to one label and only 10% belongs to another label. Can this still work?
ANSWER: Not very well. The more balanced your data, the better your model accuracy will be for predicting all possible labels. If you have mostly one label (such as in the case where say 90% of the students were “Admit”) then the model will only “see” Admit examples and so likely only predict Admit results.
5. What is cross-validation?
ANSWER: This process involves training and then testing your model multiple times with different samples of your data. For example, 5-fold cross validation means that you create a training set and a testing set (disjoint), you train the model. Then you test the model and measure the accuracy. Then you put all the data back together and repeat 4 more times.
When you review the machine learning tutorials, you will be able to review the above, see the processes in action, and go much deeper into these areas. This tutorial focuses only on methods – in R and in Python – for splitting your data into Training and Testing sets.
This last example shows a few lines of code in Python that can be used to create training and testing data from your dataset (dataframe).
from sklearn.model_selection import train_test_split
import random as rd
rd.seed(1234)
TrainDF1, TestDF1 = train_test_split(FinalDF_STEM, test_size=0.3)
## Remove and save the labels
## If you do not do this Python sklearn will not work right
## R may work - but will give you faulty results.
## Remove and save the test data labels
Test1Labels=TestDF1["Label"]
TestDF1 = TestDF1.drop(["Label"], axis=1)
print(Test1Labels)
## Remove and save the training data labels
Train1Labels=TrainDF1["Label"]
TrainDF1 = TrainDF1.drop(["Label"], axis=1)
## Now - as an example - suppose I train a Naive Bayes model
from sklearn.naive_bayes import MultinomialNB
MyModelNB1= MultinomialNB()
## Train the model. Notice that you give it the data and the labels
## separately!
MyModelNB1.fit(TrainDF1, Train1Labels)
## Check the accuracy of the model - use it to predict
Prediction1 = MyModelNB1.predict(TestDF1)
## Create a confusion matrix of the results
from sklearn.metrics import confusion_matrix
cnf_matrix1 = confusion_matrix(Test1Labels, Prediction1)
print("\nThe confusion matrix is:")
print(cnf_matrix1)